
El poder de la visualización de datos en la Optimización
Muchos grandes avances en las disciplinas técnicas surgen de aprovechar y reutilizar técnicas de otros campos que puedan aportar valor a nuestro sector. Las comunicaciones móviles no son una excepción y tanto en su arquitectura como en su gestión nos encontramos tecnologías importadas como la virtualización o las infraestructuras de Big Data.
En el ámbito de la optimización, entendida como la mejora del desempeño de la red en cualquiera de sus vertientes, el aspecto más innovador que hemos incorporado es la capacidad de visualización y análisis de datos complejos, más allá de lo que las hojas de cálculo habituales pueden gestionar. Como parte del proceso de actualización del Máster en Ingeniería de Comunicaciones Móviles se incorporan estos contenidos cada vez más demandados por la industria
¿De dónde procede este repentino interés? Principalmente de un cambio de enfoque a la hora de resolver problemas de red, que en los últimos años está alejándose del análisis de lo particular buscando tendencias que ayuden a converger rápidamente a una solución óptima. En ningún caso se trata de desestimar el potencial del estudio de los elementos de red más degradados, sino de un acercamiento distinto al proceso de optimización.
Las alternativas
La metodología Top-Down tradicional parte de un conjunto de datos previamente agregados que se pueden analizar de manera sencilla mediante unos indicadores clave o KPIs deseados. Una vez detectada una contingencia que debe ser abordada por parte del ingeniero de acceso radio, se localizan los elementos de red que más desvío presentan en el indicador elegido y se comienza un proceso de análisis individualizado que requiere de indicadores cada vez más sofisticados.
Hasta hace poco resultaba imposible intentar partir de los datos no agregados de los elementos de red, y más aún si no nos queremos limitar a un número reducido de contadores. El volumen de información necesario, que se incrementaría en la medida que se necesitase un histórico mayor o una resolución temporal más detallada, impedía que ningún análisis medianamente complejo se pudiera implementar con éxito.
Al lector le resultará evidente que el mundo actual funciona con bases de datos cada vez mayores, que gestionan información cada vez más ecléctica. Seguramente le serán familiares los conceptos de Big Data, computación distribuida y resto de herramientas que muchos sectores han acogido con entusiasmo para enfrentarse al tipo de problemas que se están describiendo en esta entrada. El análisis del rendimiento de la red no está exento de estas plataformas y durante las sesiones de Optimización E2E y CEM del Máster en Ingeniería de Comunicaciones Móviles se plantean problemas y soluciones concretas que han necesitado de clusterización computacional.
Sin embargo, esta entrada es menos ambiciosa y más cercana a procesos diarios del trabajo de la ingeniería de red. Las técnicas de análisis de datos y visualización no requieren de Spark, HDFS, Cassandra DB ni un almacenamiento en AWS, sino que están a disposición de todos los optimizadores para facilitar su trabajo y mejorar la presentación del mismo. Podríamos extendernos mucho en la importancia de dicha presentación pero creo que es de sobra conocido el énfasis que desde el MICM hacemos en la calidad de las presentaciones así que vayamos al grano.
Hay multitud de herramientas de visualización de datos con mayor o menor capacidad de analítica incorporada. Desde nuestra experiencia podemos hablar con conocimiento de causa de suites comerciales extremadamente populares como Qlik o Microsoft Power BI, muy en auge dentro de corporaciones por su integración con el resto de la suite Office. Ambas incorporan métodos propios para construir datos visualmente atractivos, enlazar tablas heterogéneas o añadir código en R, por ejemplo, para completar las necesidades del usuario.
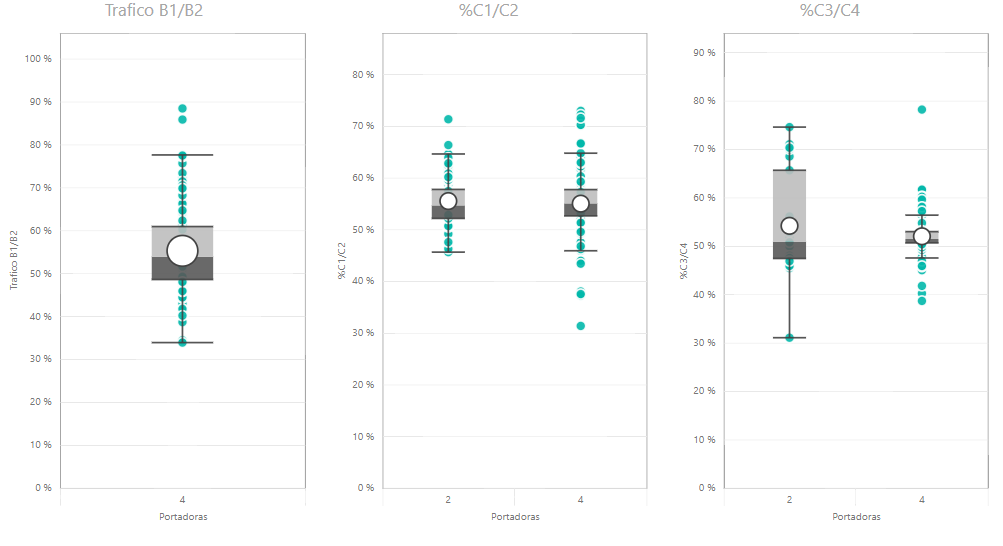 Ejemplo de representación usando Microsoft Power BI
Ejemplo de representación usando Microsoft Power BI
En ocasiones resulta excesivo en tiempo y esfuerzo cargar los datos en la herramienta, formatearlos si presentan problemas, preparar el layout de los gráficos y mapas que se quieren generar, etc. Sobre todo si se trata de responder a preguntas concretas sobre un conjunto de datos ¿qué tipo de fallos de acceso o caídas tiene mi red LTE? ¿dependen las caídas de voz que estoy viendo en una red WCDMA de los niveles de ruido UL o más bien de la falta de potencia en DL? Preguntas concretas que requieren de respuestas sencillas, rápidas y justificables. Necesitamos proporcionar soporte gráfico a la respuesta para convencer de nuestras conclusiones.
Utilizar código en python o R directamente es muchas veces lo más ágil y lo menos engorroso. Sí, es evidente que se requiere de una curva de aprendizaje mayor que la de PowerBI, pero una vez familiarizados la versatilidad y la velocidad conquistarán el corazón de cualquier ingeniero de optimización. Completamos esta propuesta con un ejemplo, precisamente la respuesta a la segunda pregunta que nos hacíamos ¿Hay un sesgo de mis caídas de voz de manera general hacia las celdas con mayor interferencia? Estamos de acuerdo en que no se trata de una duda innovadora, pero sirve de ejemplo para presentar un caso de uso sencillo. Vamos allá.
Nuestro ejemplo
Partimos de dos ficheros distintos, uno que incluye la información de tipos de caídas de voz por celda y periodo temporal de toda la red y otro que proporciona datos de consumo de potencia por celda y mismo periodo temporal. Son datos en bruto sin preprocesar. Importamos los módulos necesarios y comenzamos:
import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import numpy as np import seaborn as sns df = pd.read_excel('caidas.xlsx') cap = pd.read_excel('cap.xlsx')
¿Qué contadores incorporan los ficheros? Con comandos como describe() aplicados a ambos dataframes podemos identificar los nombres de las variables, sus máximos, si hay valores no válidos que debamos sustituir (también con comandos sencillos como fillna()), etc. Nosotros vamos a observar primero qué tipos de caídas de voz tenemos en la red y su proporción.
(df[['Radio','IUR','IU','RNC','UE','Trans']].sum().
plot.pie(figsize=(7,7),autopct='%.2f',label='Distribución AMR Drops',colormap='winter')
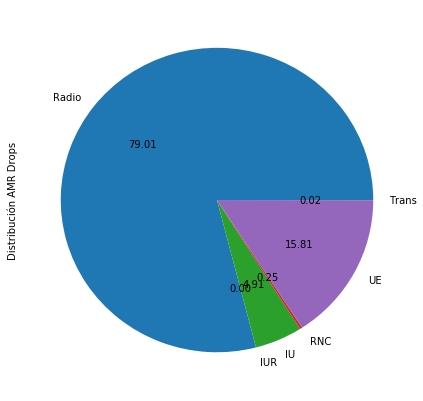
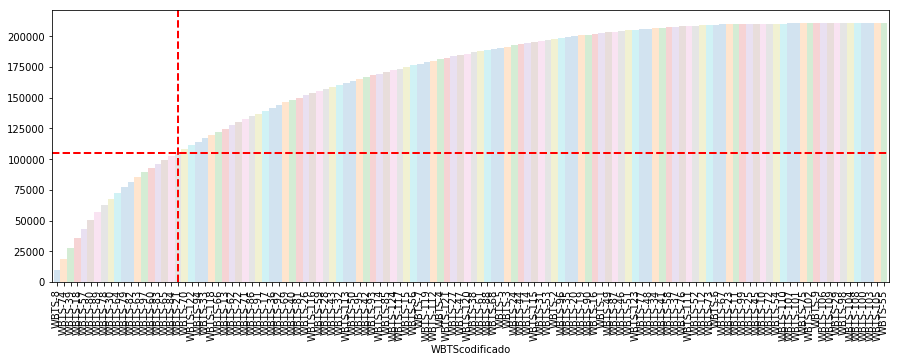
Nos cercioramos de que no existe un contador con el agregado de caídas de voz de la celda, así que lo construimos y presentamos de manera rápida el impacto del Top de peores nodos B de la red en éste indicador. Resulta inmediato chequear que 18 BTS presentan el 50% de las caídas de todo el periodo temporal considerado.
df['TotalCaidas'] = df[['Radio','IU','BTS','IUR','RNC','UE','Trans']].sum(axis=1) (ax=df.groupby(df.WBTScodificado).sum().sort_values('TotalCaidas',ascending=0). TotalCaidas.cumsum().plot(kind='bar',x='WBTScodificado',figsize=(15,5),colormap='winter',alpha=0.2,width=1,linewidth=1)) from pylab import * ax.axhline(y=df.TotalCaidas.sum()/2, xmin=0, xmax=100, color='r', linestyle='--', lw=2) ax.axvline(x=18, color='r', linestyle='--', lw=2)
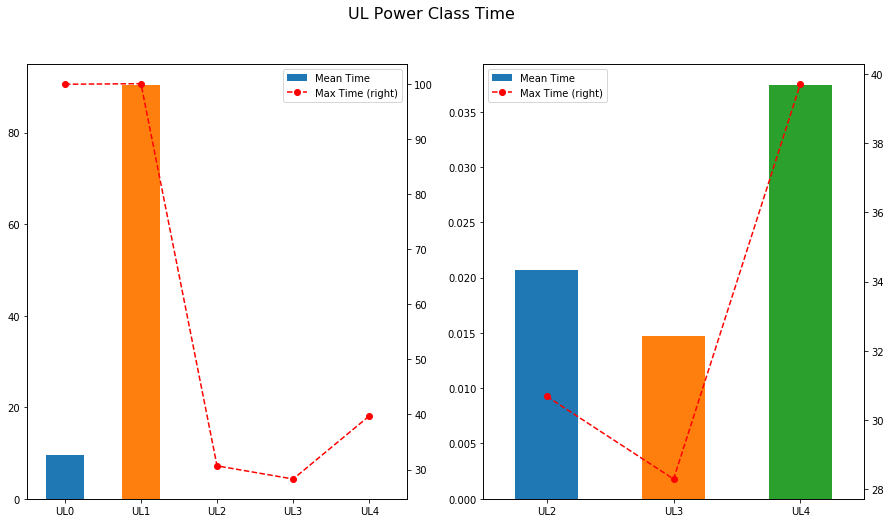
 Con respecto a la interferencia, el fichero cap.xlsx ha dado lugar al dataframe cap, con cientos de contadores asociados al consumo de potencia DL y UL de las celdas. Agregando por clases de manera similar a como hicimos con las caídas podemos representar rápidamente la cantidad de muestras medias y máximas en cada una de ellas. ¡Vaya! Resulta que hay celdas que han llegado a presentar un 40% de muestras en la zona que hemos denominado 4 (sobrecarga), lo que es bastante preocupante. En términos medios, sin embargo, se perdería esa información al no suponer más del 0,035% del tiempo total de la red.
Con respecto a la interferencia, el fichero cap.xlsx ha dado lugar al dataframe cap, con cientos de contadores asociados al consumo de potencia DL y UL de las celdas. Agregando por clases de manera similar a como hicimos con las caídas podemos representar rápidamente la cantidad de muestras medias y máximas en cada una de ellas. ¡Vaya! Resulta que hay celdas que han llegado a presentar un 40% de muestras en la zona que hemos denominado 4 (sobrecarga), lo que es bastante preocupante. En términos medios, sin embargo, se perdería esa información al no suponer más del 0,035% del tiempo total de la red.
fig, axes = plt.subplots(nrows=1, ncols=2,figsize=(15,8)) plt.suptitle('UL Power Class Time',fontsize=16) (cap[['UL0','UL1','UL2','UL3','UL4']].mean().plot. bar(ax=axes[0],label='Mean Time',legend=True)) (cap[['UL0','UL1','UL2','UL3','UL4']].max().plot. line(secondary_y=True,ax=axes[0],label='Max Time',legend=True,color='red',linestyle='--',marker='o')) cap[['UL2','UL3','UL4']].mean().plot.bar(ax=axes[1],label='Mean Time',legend=True) cap[['UL2','UL3','UL4']].max().plot. line(secondary_y=True,ax=axes[1],label='Max Time',legend=True,color='red',linestyle='--',marker='o')
Unos histogramas nos van a permitir seguir caracterizando nuestra red ¿os parecen correctos esos valores de interferencia en UL? ¿Y esa carga (entendida como noise rise)? Las diferentes bandas no parecen comportarse igual…
NR = cap.Ulavg - cap.Ulnoise fig,axe = plt.subplots(nrows=1,ncols=2,figsize=(18,5),fontsize=14) (cap.Ulnoise.plot. hist(density=1,bins=300,alpha=0.4,label='PrxNoise Histogram',legend='True',ax=axe[0,1])) (cap.Ulavg.plot. hist(density=1,bins=300,alpha=0.4,label='PrxTotal Histogram',legend='True',ax=axe[0,1])) (NR.plot. hist(cumulative=True,bins=300,alpha=0.4,label='Noise Rise Histrogram',legend='True',ax=axe[1,1])) (cap.groupby(cap.Banda).HSUPAmax.plot. hist(legend=True,alpha=0.6,grid=False, bins=28,ax=axe[1,0],title='Interferencia HSUPA')) (cap.groupby(cap.Banda).Ulavg.plot. hist(legend=True,alpha=0.6,grid=False, bins=28,ax=axe[1,1],title='Interferencia R99'))
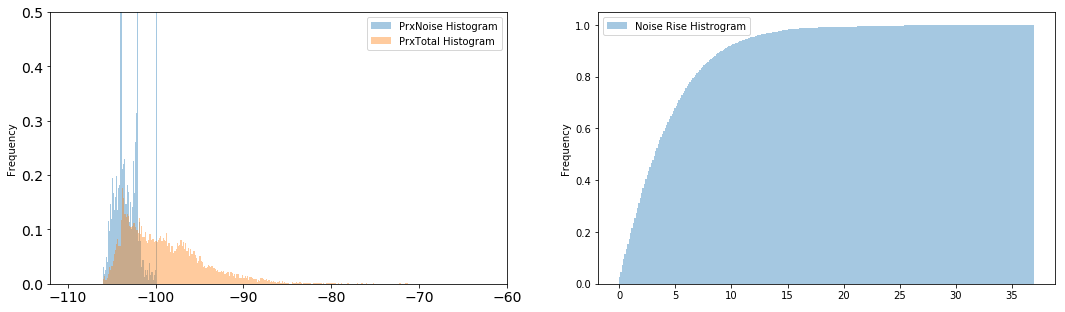
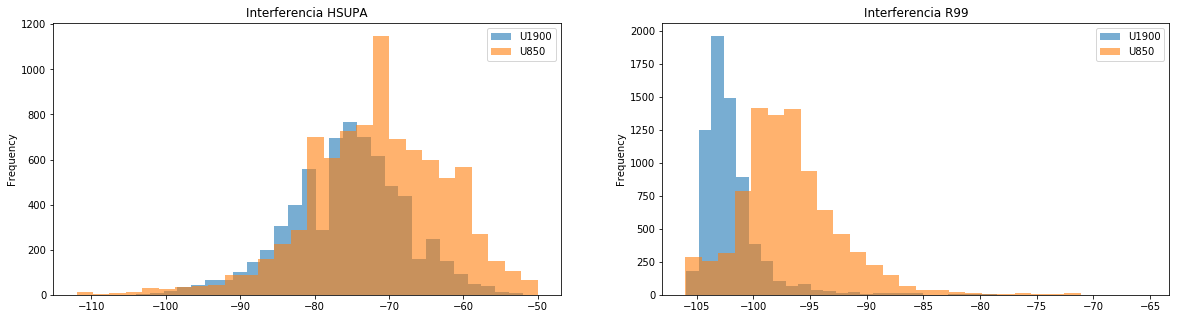
Por último, respondamos a la pregunta ¿hay relación entre la interferencia que estamos viendo en el sistema y las celdas con peores índices de llamadas caídas?
df.set_index(df['id'],inplace=True) cap.set_index(cap['id'],inplace=True) correl = pd.concat([df,cap],axis=1,sort='True') fig,axe = plt.subplots(ncols=2,figsize=(20,6),sharey=True) plt.ylim([90,100]) plt.suptitle('Retainability vs Interferencia UL',fontsize=16) rg1=sns.regplot(x=correl.Ulavg,y=correl['1-dcr'],color='orange',marker='.',ax=axe[0], ci=100) rg2=sns.regplot(x=correl.HSUPAavg,y=correl['1-dcr'],color='red',marker='.',ax=axe[1], ci=100)
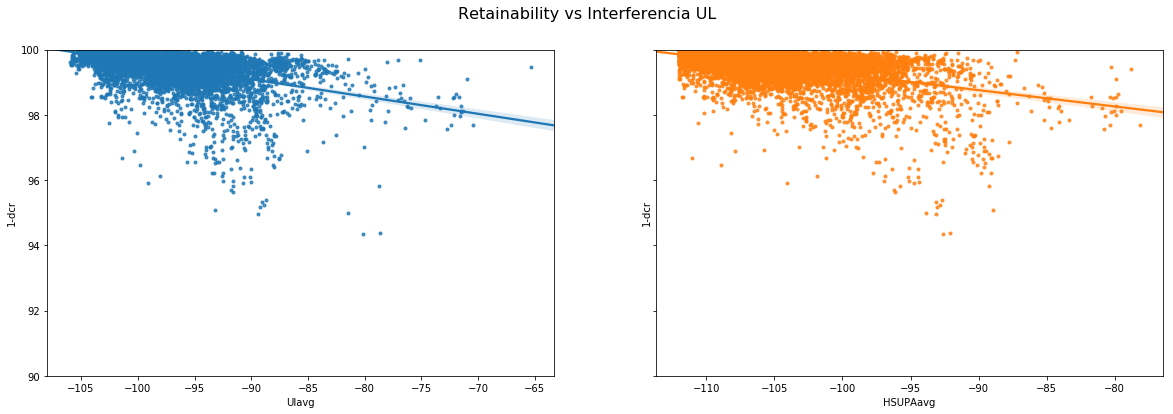
Podemos responder que sí, existe una tendencia indudable que nos permitiría atacar al problema (elevada tasa de caídas) directamente desde una de sus causas. La cuestión podría haberse acotado sin apenas modificar el código a las instancias en que el DCR se encuentra degradado para eliminar componentes irrelevantes desde el punto de vista de la optimización, limitarlo a elementos con un mínimo número de conexiones, entre otras muchas opciones de filtrado y/o agrupación.
Conclusiones
Por último, toca valorar el proceso seguido. ¿Se podría haber realizado en Excel? Sin lugar a dudas, sí. No hubiera sido inmediato trabajar sobre cientos de miles de líneas y con toda seguridad el resultado sería algo pesado pero posible. ¿Y con Qlik? Indudablemente, con más opciones y con toda seguridad más bonito. Pero no así de rápido ni así de ligero computacionalmente hablando: ejecutar todo este código apenas ha costado unos segundos de nuestro tiempo, poco más el escribirlo.
No abogamos por un uso indiscriminado de este tipo de soluciones, hay muchas cosas que seguimos haciendo en Excel y eso no va a cambiar. Tampoco lo preferimos a los Qlik, Tableau, PBI aplicados a la ingeniería de red, de hecho son herramientas que usamos con mucha más frecuencia que un Notebook de Python (cualquier lector familiarizado con el lenguaje habrá notado que no somos expertos programadores, aunque en nuestra descarga se buscaba generar un ejemplo lo más rápido y compacto posible).
Lo que queremos es recomendar la formación en análisis de datos, en visualización de los mismos, en lenguajes como R o Python, para cualquier disciplina donde el elemento de trabajo fundamental sea la información. Por eso el Máster en Ingeniería de Comunicaciones Móviles incluye desde esta edición una asignatura a este respecto donde abrir la mente a los alumnos acerca de la potencia que pueden incorporar a sus trabajos.
¿Hemos mencionado ya el Machine Learning? Bueno, mejor lo dejamos para otro día.